
Microsoft has a history of 48 years since its establishment. It is the largest software manufacturer in the world. Microsoft has achieved a lot of careers and a large number of information technology talents! You must know that he is one of the five giants in the United States. It is absolutely a great honor to be a member of Microsoft. To be a member of Microsoft, at least you need to have a Microsoft certification.
Today I introduce to you Exam DP-100: Designing and Implementing a Data Science Solution on Azure.
A candidate for this certification should have knowledge and experience in data science and using Azure Machine Learning and Azure Databricks.
And I am here to help you learn the latest exam knowledge effectively and share the latest exam content. The important thing is that you can choose directly Azure DP-100 Dumps: https://www.leads4pass.com/dp-100.html (311 Q&A). leads4pass Can directly help you pass the exam easily.
And share the Azure DP-100 exam online exam test (part of the leads4pass DP-100 dump) or download the free DP-100 PDF: https://drive.google.com/file/d/1ERokPE8byaytg4mD7AOm74gY88zqIB-j/
Azure DP-100 online exam (answers posted at the end of the article):
QUESTION 1
HOTSPOT
You need to identify the methods for dividing the data according to the testing requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
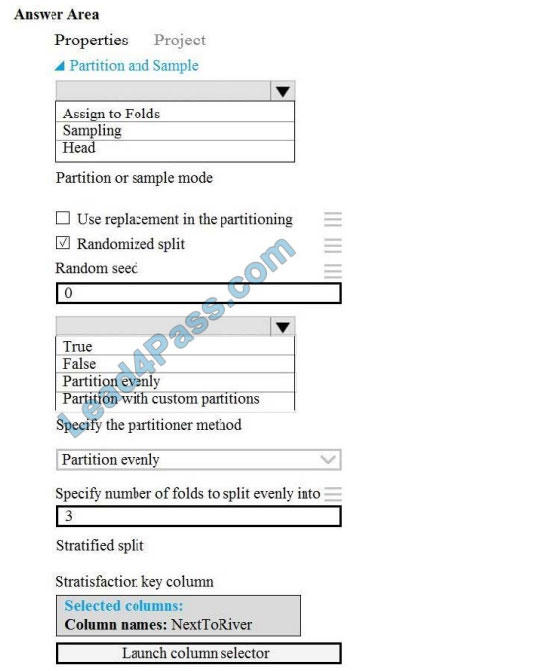
Correct Answer:
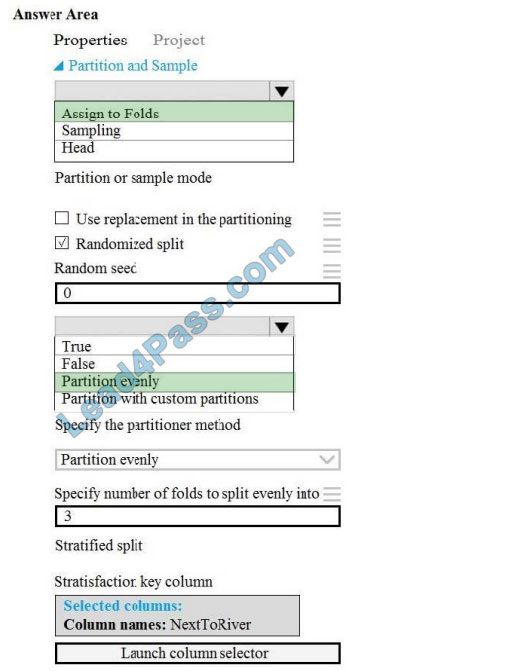
Scenario: Testing
You must produce multiple partitions of a dataset based on sampling using the Partition and Sample module in Azure
Machine Learning Studio.
Box 1: Assign to folds
Use Assign to folds option when you want to divide the dataset into subsets of the data. This option is also useful when you want to create a custom number of folds for cross-validation, or to split rows into several groups.
Not Head: Use Head mode to get only the first n rows. This option is useful if you want to test a pipeline on a small
number of rows, and don\\’t need the data to be balanced or sampled in any way.
Not Sampling: The Sampling option supports simple random sampling or stratified random sampling. This is useful if
you want to create a smaller representative sample dataset for testing.
Box 2: Partition evenly
Specify the partitioner method: Indicate how you want data to be apportioned to each partition, using these options:
Partition evenly: Use this option to place an equal number of rows in each partition. To specify the number of output
partitions, type a whole number in the Specify number of folds to split evenly into text box.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/algorithm-module-reference/partition-and-sample
QUESTION 2
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
You are creating a model to predict the price of a student\\’s artwork depending on the following variables:
the student\\’s length of education, degree type, and art form.
You start by creating a linear regression model.
You need to evaluate the linear regression model.
Solution: Use the following metrics: Accuracy, Precision, Recall, F1 score, and AUC.
Does the solution meet the goal?
A. Yes
B. No
Those are metrics for evaluating classification models, instead use: Mean Absolute Error, Root Mean Absolute Error,
Relative Absolute Error, Relative Squared Error, and the Coefficient of Determination.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/evaluate-model
QUESTION 3
You have a Python data frame named salesData in the following format:

You need to use the pandas.melt() function in Python to perform the transformation.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
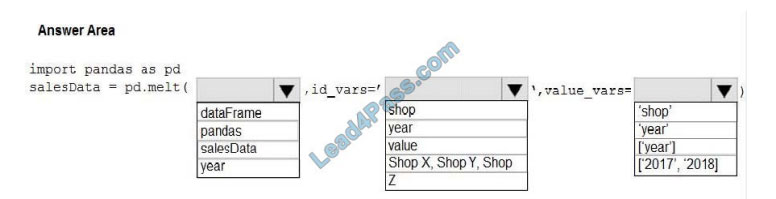
Correct Answer:

Box 1: dataFrame
Syntax: pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name=\\’value\\’,
col_level=None)[source]
Where frame is a DataFrame
Box 2: shop
Paramter id_vars id_vars : tuple, list, or ndarray, optional
Column(s) to use as identifier variables.
Box 3: [\\’2017\\’,\\’2018\\’]
value_vars : tuple, list, or ndarray, optional
Column(s) to unpivot. If not specified, uses all columns that are not set as id_vars.
Example:
df = pd.DataFrame({\\’A\\’: {0: \\’a\\’, 1: \\’b\\’, 2: \\’c\\’},
… \\’B\\’: {0: 1, 1: 3, 2: 5},
… \\’C\\’: {0: 2, 1: 4, 2: 6}})
pd.melt(df, id_vars=[\\’A\\’], value_vars=[\\’B\\’, \\’C\\’]) A variable value
0 a B 1
1 b B 3
2 c B 5
3 a C 2
4 b C 4
5 c C 6
References: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.melt.html
QUESTION 4
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
You train a classification model by using a logistic regression algorithm.
You must be able to explain the model\\’s predictions by calculating the importance of each feature, both as an overall
global relative importance value and as a measure of local importance for a specific set of predictions.
You need to create an explainer that you can use to retrieve the required global and local feature importance values.
Solution: Create a PFIExplainer.
Does the solution meet the goal?
A. Yes
B. No
Permutation Feature Importance Explainer (PFI): Permutation Feature Importance is a technique used to explain
classification and regression models. At a high level, the way it works is by randomly shuffling data one feature at a time for the entire dataset and calculating how much the performance metric of interest changes. The larger the change, the more important that feature is. PFI can explain the overall behavior of any underlying model but does not explain individual predictions.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-machine-learning-interpretability
QUESTION 5
You create a batch inference pipeline by using the Azure ML SDK. You configure the pipeline parameters by executing
the following code:

You need to obtain the output from the pipeline execution. Where will you find the output?
A. the digit_identification.py script
B. the debug log
C. the Activity Log in the Azure portal for the Machine Learning workspace
D. the Inference Clusters tab in Machine Learning studio
E. a file named parallel_run_step.txt located in the output folder
output_action (str): How the output is to be organized. Currently supported values are \\’append_row\\’ and
\\’summary_only\\’.
1.
\\’append_row\\’ ?All values output by run() method invocations will be aggregated into one unique file named
parallel_run_step.txt that is created in the output location.
2.
\\’summary_only\\’
Reference:
https://docs.microsoft.com/en-us/python/api/azureml-contrib-pipeline-steps/azureml.contrib.pipeline.steps.parallelrunconfig
QUESTION 6
You must store data in Azure Blob Storage to support Azure Machine Learning.
You need to transfer the data into Azure Blob Storage.
What are three possible ways to achieve the goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Bulk Insert SQL Query
B. AzCopy
C. Python script
D. Azure Storage Explorer
E. Bulk Copy Program (BCP)
You can move data to and from Azure Blob storage using different technologies:
1. Azure Storage-Explorer
2.AzCopy
3.Python
4.SSIS
References: https://docs.microsoft.com/en-us/azure/machine-learning/team-data-science-process/move-azure-blob
QUESTION 7
HOTSPOT
You are performing sentiment analysis using a CSV file that includes 12.0O0 customer reviews written in a short
sentence format.
You add the CSV file to Azure Machine Learning Studio and Configure it as the starting point dataset of an experiment.
You add the Extract N-Gram Features from Text module to the experiment to extract key phrases from the customer
review column in the dataset.
You must create a new n-gram text dictionary from the customer review text and set the maximum n-gram size to
trigrams.
You need to configure the Extract N Gram features from Text module.
What should you select? To answer, select the appropriate options in the answer area;
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer

QUESTION 8
You run an experiment that uses an AutoMLConfig class to define an automated machine learning task with a maximum of ten model training iterations. The task will attempt to find the best performing model based on a metric named accuracy.
You submit the experiment with the following code:

A. best_model = automl_run.get_details()
B. best_model = automl_run.get_metrics()
C. best_model = automl_run.get_file_names()[1]
D. best_model = automl_run.get_output()[1]
The get_output method returns the best run and the fitted model.
Reference:
https://notebooks.azure.com/azureml/projects/azureml-getting-started/html/how-to-use-azureml/automated-machinelearning/classification/auto-ml-classification.ipynb
QUESTION 9
HOTSPOT
You use Data Science Virtual Machines (DSVMs) for Windows and Linux in Azure.
You need to access the DSVMs.
Which utilities should you use? To answer, select the appropriate options in the answer area;
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

QUESTION 10
You plan to use the Hyperdrive feature of Azure Machine Learning to determine the optimal hyperparameter values
when training a model. You must use Hyperdrive to try combinations of the following hyperparameter values:
1.learning_rate: any value between 0.001 and 0.1
2.batch_size: 16, 32, or 64
You need to configure the search space for the Hyperdrive experiment.
Which two parameter expressions should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. a choice expression for learning_rate
B. a uniform expression for learning_rate
C. a normal expression for batch_size
D. a choice expression for batch_size
E. a uniform expression for batch_size
B: Continuous hyperparameters are specified as a distribution over a continuous range of values.
Supported distributions include:
uniform(low, high) – Returns a value uniformly distributed between low and high
D: Discrete hyperparameters are specified as a choice among discrete values. choice can be:
1.one or more comma-separated values
2.a range object
3.any arbitrary list object
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-tune-hyperparameters
QUESTION 11
Your team is building a data engineering and data science development environment. The environment must support
the following requirements:
1.support Python and Scala
2.compose data storage, movement, and processing services into automated data pipelines
3.the same tool should be used for the orchestration of both data engineering and data science
4.support workload isolation and interactive workloads
5.enable scaling across a cluster of machines
You need to create the environment.
What should you do?
A. Build the environment in Apache Hive for HDInsight and use Azure Data Factory for orchestration.
B. Build the environment in Azure Databricks and use Azure Data Factory for orchestration.
C. Build the environment in Apache Spark for HDInsight and use Azure Container Instances for orchestration.
D. Build the environment in Azure Databricks and use Azure Container Instances for orchestration.
In Azure Databricks, we can create two different types of clusters.
1.Standard, these are the default clusters and can be used with Python, R, Scala and SQL
2.High-concurrency
Azure Databricks is fully integrated with Azure Data Factory.
Incorrect Answers:
D: Azure Container Instances is good for development or testing. Not suitable for production workloads.
References:
https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/data-science-and-machine-learning
QUESTION 12
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
An IT department creates the following Azure resource groups and resources:

The IT department creates an Azure Kubernetes Service (AKS)-based inference compute target named aks-cluster in
the Azure Machine Learning workspace.
You have a Microsoft Surface Book computer with a GPU. Python 3.6 and Visual Studio Code are installed.
You need to run a script that trains a deep neural network (DNN) model and logs the loss and accuracy metrics.
Solution: Install the Azure ML SDK on the Surface Book. Run Python code to connect to the workspace and then run
the training script as an experiment on local compute.
Does the solution meet the goal?
A. Yes
B. No
Need to attach the mlvm virtual machine as a compute target in the Azure Machine Learning workspace.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/concept-compute-target
Verify answer:
| Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | Q10 | Q11 | Q12 |
| IMAGE | B | IMAGE | A | E | BCD | IMAGE | D | IMAGE | BD | B | B |
leads4pass DP-100 Dumps has complete exam questions with both PDF and VCE modes Guaranteed 100% pass exam DP-100 Dumps:[2022] https://www.leads4pass.com/dp-100.html (311 Q&A)
Maybe you want to ask:
Can leads4pass help me pass the exam successfully?
leads4pass has a 99%+ exam pass rate, this is real data.
Is leads4pass DP-100 dumps latest valid?
leads4pass updates all IT certification exam questions throughout the year. Guaranteed immediate availability.
Is the leads4pass buying policy reliable?
leads4pass has 8 years of exam experience in 2022, so it’s pretty solid!
Is there a discount on Azure DP-100?
Yes! You can google search, or check the discount code channel directly
For more questions, you can contact leads4pass customer service or send an email, and we will guarantee a reply within 24 hours.
PS.: Download DP-100 Dumps PDF: https://drive.google.com/file/d/1ERokPE8byaytg4mD7AOm74gY88zqIB-j/