leads4pass has updated Microsoft DP-201 dumps issues! The latest DP-201 exam questions can help you pass the exam! All questions are corrected to ensure authenticity and effectiveness! Download the leads4pass DP-201 VCE dump or PDF dumps: https://www.leads4pass.com/dp-201.html (Total Questions: 164 Q&A DP-201 Dumps)
Microsoft DP-201 Practice testing questions from Youtbe
Dumpsdemo Exam Table of Contents:
- Latest Microsoft DP-201 google drive
- Effective Microsoft DP-201 Practice testing questions
- leads4pass Year-round Discount Code
- What are the advantages of leads4pass?
Latest Microsoft DP-201 google drive
[PDF] Free Microsoft DP-201 pdf dumps download from Google Drive: https://drive.google.com/file/d/1OnBb9I2qIbSg248c63fHtchcZUFR1lQk/
The latest update of Microsoft DP-201 exam questions and answers and official exam information tips
[2021.5 updated]: https://www.fulldumps.com/microsoft-dp-201-exam-dumps-and-online-practice-questions-are-available-from-leads4pass-2/
Exam DP-201: Designing an Azure Data Solution
A NEW VERSION OF THIS EXAM, DP-203, IS AVAILABLE. You will be able to take this exam until it retires on June 30, 2021. Note: Exams retire at 11:59 PM Central Standard Time. [Get complete DP-203 exam questions and answers ]
Latest updates Microsoft DP-201 exam practice questions
QUESTION 1
You need to design the solution for analyzing customer data.
What should you recommend?
A. Azure Databricks
B. Azure Data Lake Storage
C. Azure SQL Data Warehouse
D. Azure Cognitive Services
E. Azure Batch
Correct Answer: A
Customer data must be analyzed using managed Spark clusters.
You create spark clusters through Azure Databricks.
References:
https://docs.microsoft.com/en-us/azure/azure-databricks/quickstart-create-databricks-workspace-portal
QUESTION 2
You are designing an Azure Cosmos DB database that will support vertices and edges. Which Cosmos DB API should you include in the design?
A. SQL
B. Cassandra
C. Gremlin
D. Table
Correct Answer: C
The Azure Cosmos DB Gremlin API can be used to store massive graphs with billions of vertices and edges.
References: https://docs.microsoft.com/en-us/azure/cosmos-db/graph-introduction
QUESTION 3
You are designing a real-time stream solution based on Azure Functions. The solution will process data uploaded to
Azure Blob Storage. The solution requirements are as follows:
1. New blobs must be processed with a little delay as possible.
2.
Scaling must occur automatically.
3.
Costs must be minimized. What should you recommend?
A. Deploy the Azure Function in an App Service plan and use a Blob trigger.
B. Deploy the Azure Function in a Consumption plan and use an Event Grid trigger.
C. Deploy the Azure Function in a Consumption plan and use a Blob trigger.
D. Deploy the Azure Function in an App Service plan and use an Event Grid trigger.
Correct Answer: C
Create a function, with the help of a blob trigger template, which is triggered when files are uploaded to or updated in
Azure Blob storage. You use a consumption plan, which is a hosting plan that defines how resources are allocated to
your function app. In the default Consumption Plan, resources are added dynamically as required by your functions. In
this serverless hosting, you only pay for the time your functions run. When you run in an App Service Plan, you must
manage the scaling of your function app.
References: https://docs.microsoft.com/en-us/azure/azure-functions/functions-create-storage-blob-triggered-function
QUESTION 4
You need to optimize storage for CONT_SQL3.
What should you recommend?
A. AlwaysOn
B. Transactional processing
C. General
D. Data warehousing
Correct Answer: B
CONT_SQL3 with the SQL Server role, 100 GB database size, Hyper-VM to be migrated to Azure VM. The storage
should be configured to optimized storage for database OLTP workloads.
Azure SQL Database provides three basic in-memory based capabilities (built into the underlying database engine) that
can contribute in a meaningful way to performance improvements:
In-Memory Online Transactional Processing (OLTP) Clustered column store indexes intended primarily for Online
Analytical Processing (OLAP) workloads Nonclustered column store indexes geared towards Hybrid
Transactional/Analytical Processing (HTAP) workloads
References: https://www.databasejournal.com/features/mssql/overview-of-in-memory-technologies-of-azure-sql-database.html
QUESTION 5
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear on the review screen.
You are designing an HDInsight/Hadoop cluster solution that uses Azure Data Lake Gen1 Storage.
The solution requires POSIX permissions and enables diagnostics logging for auditing.
You need to recommend solutions that optimize storage.
Proposed Solution: Implement compaction jobs to combine small files into larger files.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: A
Depending on what services and workloads are using the data, a good size to consider for files is 256 MB or greater. If
the file sizes cannot be batched when landing in Data Lake Storage Gen1, you can have a separate compaction job that
combines these files into larger ones.
Note: POSIX permissions and auditing in Data Lake Storage Gen1 comes with an overhead that becomes apparent
when working with numerous small files. As a best practice, you must batch your data into larger files versus writing
thousands or millions of small files to Data Lake Storage Gen1. Avoiding small file sizes can have multiple benefits,
such as:
1.
Lowering the authentication checks across multiple files
2.
Reduced open file connections
3.
Faster copying/replication
4.
Fewer files to process when updating Data Lake Storage Gen1 POSIX permissions
References: https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-best-practices
QUESTION 6
You need to ensure that emergency road response vehicles are dispatched automatically.
How should you design the processing system? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
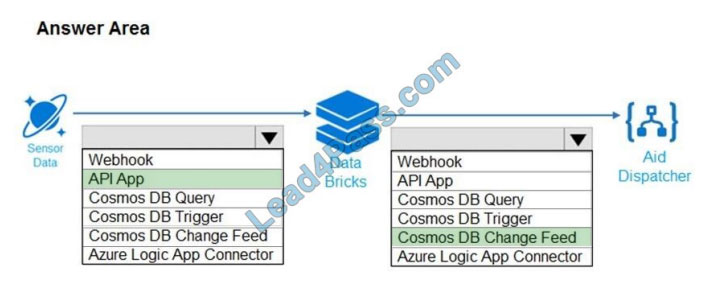
Explanation: Box1: API App
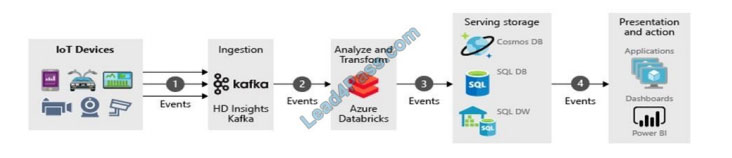
Events generated from the IoT data sources are sent to the stream ingestion layer through Azure HDInsight Kafka as a
stream of messages. HDInsight Kafka stores a stream of data in topics for a configurable of time.
Kafka consumer, Azure Databricks, picks up the message in real-time from the Kafka topic, to process the data based
on the business logic and can then send to the Serving layer for storage.
Downstream storage services, like Azure Cosmos DB, Azure SQL Data warehouse, or Azure SQL DB, will then be a data source for the presentation and action layer.
Business analysts can use Microsoft Power BI to analyze warehoused data. Other applications can be built upon the
serving layer as well. For example, we can expose APIs based on the service layer data for third party uses.
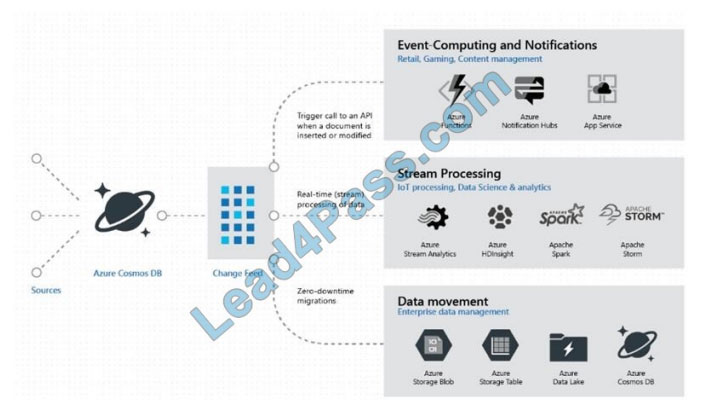
Box 2: Cosmos DB Change Feed
Change feed support in Azure Cosmos DB works by listening to an Azure Cosmos DB container for any changes. It
then outputs the sorted list of documents that were changed in the order in which they were modified.
The change feed in Azure Cosmos DB enables you to build efficient and scalable solutions for each of these patterns,
as shown in the following image:
QUESTION 7
You need to design the disaster recovery solution for customer sales data analytics.
Which three actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Provision multiple Azure Databricks workspaces in separate Azure regions.
B. Migrate users, notebooks, and cluster configurations from one workspace to another in the same region.
C. Use zone redundant storage.
D. Migrate users, notebooks, and cluster configurations from one region to another.
E. Use Geo-redundant storage.
F. Provision a second Azure Databricks workspace in the same region.
Correct Answer: ADE
Scenario: The analytics solution for customer sales data must be available during a regional outage.
To create your own regional disaster recovery topology for data bricks, follow these requirements:
Provision multiple Azure Databricks workspaces in separate Azure regions
Use Geo-redundant storage.
Once the secondary region is created, you must migrate the users, user folders, notebooks, cluster configuration, jobs
configuration, libraries, storage, init scripts and reconfigure access control.
Note: Geo-redundant storage (GRS) is designed to provide at least 99.99999999999999% (16 9\\’s) durability of objects
over a given year by replicating your data to a secondary region that is hundreds of miles away from the primary region.
If
your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a
disaster in which the primary region isn\\’t recoverable.
References:
https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
QUESTION 8
A company is developing a mission-critical line of business app that uses Azure SQL Database Managed Instance.
You must design a disaster recovery strategy for the solution/You need to ensure that the database automatically recovers when the full or partial loss of the Azure SQL Database
service occurs in the primary region.
What should you recommend?
A. Failover-group
B. Azure SQL Data Sync
C. SQL Replication
D. Active geo-replication
Correct Answer: A
Auto-failover groups is a SQL Database feature that allows you to manage replication and failover of a group of
databases on a SQL Database server or all databases in a Managed Instance to another region (currently in public
preview for Managed Instance). It uses the same underlying technology as active geo-replication. You can initiate
failover manually or you can delegate it to the SQL Database service based on a user-defined policy.
References: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-auto-failover-group
QUESTION 9
You are designing a data storage solution for a database that is expected to grow to 50 TB. The usage pattern is
singleton inserts, singleton updates, and reporting. Which storage solution should you use?
A. Azure SQL. Database elastic pools
B. Azure SQL Data Warehouse
C. Azure Cosmos DB that uses the Gremlin API
D. Azure SQL Database Hyperscale
Correct Answer: D
A Hyperscale database is an Azure SQL database in the Hyperscale service tier that is backed by the Hyperscale scaleout storage technology. A Hyperscale database supports up to 100 TB of data and provides high throughput and
performance, as well as rapid scaling to adapt to the workload requirements. Scaling is transparent to the application
?connectivity, query processing, etc. work like any other Azure SQL database.
Incorrect Answers:
A: SQL Database elastic pools are a simple, cost-effective solution for managing and scaling multiple databases that
have varying and unpredictable usage demands. The databases in an elastic pool are on a single Azure SQL Database
server and share a set number of resources at a set price. Elastic pools in Azure SQL Database enable SaaS
developers to optimize the price performance for a group of databases within a prescribed budget while delivering
performance elasticity for each database.
B: Rather than SQL Data Warehouse, consider other options for operational (OLTP) workloads that have large numbers
of singleton selects.
References: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-service-tier-hyperscale-faq
QUESTION 10
A company manufactures automobile parts. The company installs IoT sensors on manufacturing machinery.
You must design a solution that analyzes data from the sensors.
You need to recommend a solution that meets the following requirements:
1.
Data must be analyzed in real-time.
2.
Data queries must be deployed using continuous integration.
3.
Data must be visualized by using charts and graphs.
4.
Data must be available for ETL operations in the future.
5.
The solution must support high-volume data ingestion.
Which three actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Use Azure Analysis Services to query the data. Output query results to Power BI.
B. Configure an Azure Event Hub to capture data to Azure Data Lake Storage.
C. Develop an Azure Stream Analytics application that queries the data and outputs to Power BI. Use Azure Data
Factory to deploy the Azure Stream Analytics application.
D. Develop an application that sends the IoT data to an Azure Event Hub.
E. Develop an Azure Stream Analytics application that queries the data and outputs to Power BI. Use Azure Pipelines to
deploy the Azure Stream Analytics application.
F. Develop an application that sends the IoT data to an Azure Data Lake Storage container.
Correct Answer: BCD
QUESTION 11
You are designing an application. You plan to use Azure SQL Database to support the application.
The application will extract data from the Azure SQL Database and create text documents. The text documents will be placed into a cloud-based storage solution. The text storage solution must be accessible from an SMB network share.
You need to recommend a data storage solution for the text documents.
Which Azure data storage type should you recommend?
A. Queue
B. Files
C. Blob
D. Table
Correct Answer: B
Azure Files enables you to set up highly available network file shares that can be accessed by using the standard
Server Message Block (SMB) protocol. Incorrect Answers:
A: The Azure Queue service is used to store and retrieve messages. It is generally used to store lists of messages to be
processed asynchronously.
C: Blob storage is optimized for storing massive amounts of unstructured data, such as text or binary data. Blob storage
can be accessed via HTTP or HTTPS but not via SMB.
D: Azure Table storage is used to store large amounts of structured data. Azure tables are ideal for storing structured,
non-relational data.
References: https://docs.microsoft.com/en-us/azure/storage/common/storage-introduction https://docs.microsoft.com/enus/azure/storage/tables/table-storage-overview
QUESTION 12
You need to recommend the appropriate storage and processing solution?
What should you recommend?
A. Enable auto-shrink on the database.
B. Flush the blob cache using Windows PowerShell.
C. Enable Apache Spark RDD (RDD) caching.
D. Enable Databricks IO (DBIO) caching.
E. Configure the reading speed using Azure Data Studio.
Correct Answer: C
Scenario: You must be able to use a file system view of data stored in a blob. You must build an architecture that will
allow Contoso to use the DB FS filesystem layer over a blob store.
Databricks File System (DBFS) is a distributed file system installed on Azure Databricks clusters. Files in DBFS persist
to Azure Blob storage, so you won\\’t lose data even after you terminate a cluster. The Databricks Delta cache, previously named Databricks IO (DBIO) caching, accelerates data reads by creating copies
of remote files in nodes
QUESTION 13
Inventory levels must be calculated by subtracting the current day\\’s sales from the previous day\\’s final inventory.
Which two options provide Litware with the ability to quickly calculate the current inventory levels by store and product?
Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Consume the output of the event hub by using Azure Stream Analytics and aggregate the data by store and product.
Output the resulting data directly to Azure SQL Data Warehouse. Use Transact-SQL to calculate the inventory levels.
B. Output Event Hubs Avro files to Azure Blob storage. Use Transact-SQL to calculate the inventory levels by using
PolyBase in Azure SQL Data Warehouse.
C. Consume the output of the event hub by using Databricks. Use Databricks to calculate the inventory levels and
output the data to Azure SQL Data Warehouse.
D. Consume the output of the event hub by using Azure Stream Analytics and aggregate the data by store and product.
Output the resulting data into Databricks. Calculate the inventory levels in Databricks and output the data to Azure Blob
storage.
E. Output Event Hubs Avro files to Azure Blob storage. Trigger an Azure Data Factory copy activity to run every 10
minutes to load the data into Azure SQL Data Warehouse. Use Transact-SQL to aggregate the data by store and
product.
Correct Answer: AE
A: Azure Stream Analytics is a fully managed service providing low-latency, highly available, scalable complex event
processing over streaming data in the cloud. You can use your Azure SQL Data Warehouse database as an output sink
for your Stream Analytics jobs.
E: Event Hubs Capture is the easiest way to get data into Azure. Using Azure Data Lake, Azure Data Factory, and
Azure HDInsight, you can perform batch processing and other analytics using familiar tools and platforms of your
choosing, at
any scale you need.
Note: Event Hubs Capture creates files in Avro format.
Captured data is written in Apache Avro format: a compact, fast, binary format that provides rich data structures with the inline schema. This format is widely used in the Hadoop ecosystem, Stream Analytics, and Azure Data Factory.
Scenario: The application development team will create an Azure event hub to receive real-time sales data, including
store number, date, time, product ID, customer loyalty number, price, and the discount amount, from the point of sale (POS)
system and output the data to data storage in Azure.
Reference: https://docs.microsoft.com/bs-latn-ba/azure/sql-data-warehouse/sql-data-warehouse-integrate-azure-streamanalytics https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-capture-overview
Latest leads4pass Microsoft dumps Discount Code 2020

About The leads4pass Dumps Advantage
leads4pass has 7 years of exam experience! A number of professional Microsoft exam experts! Update exam questions throughout the year! The most complete exam questions and answers! The safest buying experience! The greatest free sharing of exam practice questions and answers!
Our goal is to help more people pass the Microsoft exam! Exams are a part of life, but they are important!
In the study you need to sum up the study! Trust leads4pass to help you pass the exam 100%!

Summarize:
This blog shares the latest Microsoft DP-201 exam dumps, DP-201 exam questions and answers! DP-201 pdf, DP-201 exam video!
You can also practice the test online! leads4pass is the industry leader!
Select leads4pass DP-201 exams Pass Microsoft DP-201 exams “Designing an Azure Data Solution”. Help you successfully pass the DP-201 exam.
ps.
Get Microsoft Full Series Exam Dump: https://www.fulldumps.com/?s=Microsoft (Updated daily)
Get leads4pass Azure Data Engineer Associate exam dumps: https://www.leads4pass.com/role-based.html
Latest update leads4pass DP-201 exam dumps: https://www.leads4pass.com/dp-201.html (164 Q&As)
[Q1-Q12 PDF] Free Microsoft DP-201 pdf dumps download from Google Drive: https://drive.google.com/file/d/1OnBb9I2qIbSg248c63fHtchcZUFR1lQk/